Home / Featured Work / Umbra
Umbra
I wanted to get better at speaking without crutch words, so I built an app that judges me every time I say "um."

I wanted to get better at speaking without crutch words, so I built an app that judges me every time I say "um." 😤
Meet Umbra — a real-time filler word detector with a little dude that gets visibly angry when you slip up.
Introduction
Most people don't realize how often they say "like" or "um" until someone points it out. Umbra does that in real time, without making the feedback feel robotic or punitive. The goal was simple: make speaking practice feel interactive and honest.
I designed and built the entire app solo, from speech streaming logic to character animation. This was also my first time drawing SVGs and animating with Lottie.


Highlights
- Real-time transcription via Deepgram
- Filler words highlighted as you speak
- Reactive animated character that responds to your speaking quality
- Random topic generator for impromptu speaking practice
- Customizable detection (toggle built-ins and add your own words)
- Installable as a PWA
Challenge
Real-time speech is messy. Interim transcript results constantly shift and correct themselves, so rendering live feedback smoothly (without jarring UI jumps) took careful state handling.
Then there's the "like" problem. "I, like, went to the store" is a filler. "I like cats" is not. Naive keyword matching breaks immediately, so I had to build context-aware logic that checks surrounding words before flagging anything.
Filler sounds like "uh" and "ah" were another headache. Speech-to-text transcribes them inconsistently across sessions and speakers, and it turns out this is a commonly reported issue with streaming transcription in general. It's much better now, but still an area I'm actively refining.
Solution
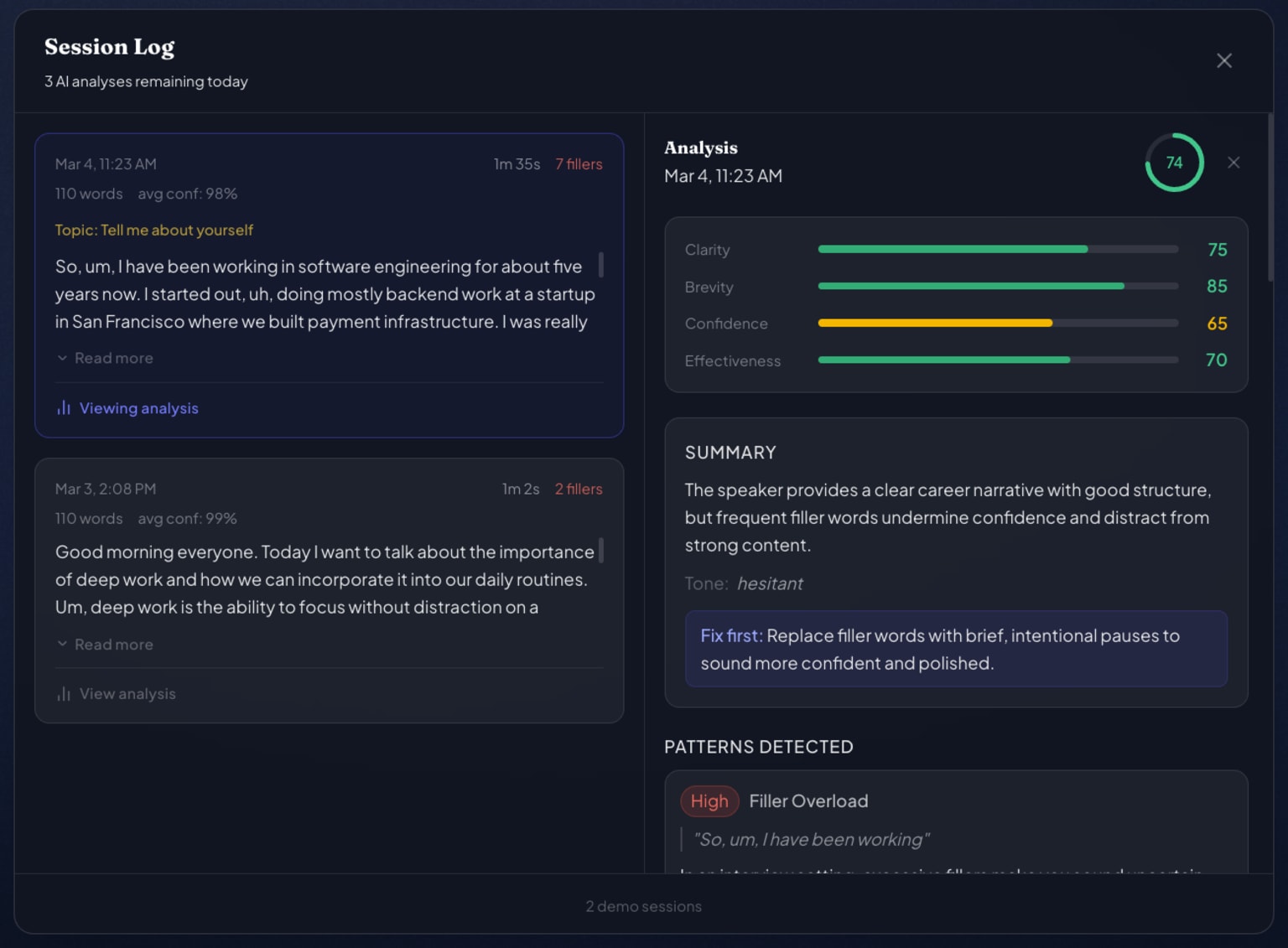
The filler detection engine uses a rule-based context analyzer that inspects the surrounding tokens before flagging a word. Rules like "like" after "I" or "you" = meaningful verb and "like" followed by "a" or "the" = comparison are evaluated against a sliding window of the live transcript. Deepgram's WebSocket SDK streams interim and final results separately, so the logic runs on final words only to avoid double-counting.
For post-session analysis, I built a DeepSeek AI integration that receives the full transcript alongside a dynamic system prompt that changes based on the selected topic mode. Practicing a job interview answer gets scored on structure, confidence, and concision — casual conversation gets different criteria entirely. The AI response is typed against a strict SessionAnalysis schema (clarity, brevity, confidence, effectiveness scores + timestamped evidence quotes) so the UI always has predictable data to render.
The animated mascot is a Lottie character that transitions between idle, happy, and angry states based on filler density in the current session window. To support user-selectable color themes, I implemented a color-space distance matching algorithm that identifies the mascot's primary hues and remaps them while preserving accent colors like the pink blush and white gloss that define the character's personality.
The full stack: Next.js 16 / React 19 / TypeScript, Deepgram SDK for streaming STT, DeepSeek via OpenAI-compatible API for analysis, Supabase for auth + usage tracking with row-level security, Tailwind CSS v4, and Lottie React for animation. Shipped as a PWA with a service worker and installable manifest.
What's next
- Feeding transcript data into an LLM for personalized speech coaching
- Tracking progress and analytics over time (I love to gamify everything)
- Improving audio processing for better performance and consistency
Conclusion
Umbra started as a personal challenge and turned into one of my favorite builds: a production-ready app with a deceptively tricky core problem, solved with real-time systems, NLP edge-case handling, and character-driven UX. The biggest lesson was balancing technical correctness with user feel — feedback had to be accurate, but also readable, responsive, and a little fun.